
Das sind wir
Digitalagentur im Herzen Berlin

Als Digitalagentur beraten und begleiten wir mittelständische und große Unternehmen in allen Phasen eines Digitalprojektes. Gemeinsam finden wir Lösungen, die Herausforderung der Digitalisierung zu meistern. Mit Neofonie stehen Ihnen 180 Spezialisten zur Seite, die mit höchstem technischen Know-how maßgeschneiderte Lösungen schaffen, die optimal auf Ihr Geschäft und Ihre Nutzer zugeschnitten sind.
Profitieren Sie von unserer mehr als 20-jährigen Praxiserfahrung in den Bereichen Commerce, Content Management, Künstliche Intelligenz und Mobile. Als Full-Service Agentur begleiten wir Sie entlang der gesamten Wertschöpfungskette – von der Idee, über das Design bis hin zum finalen Produkt. Unser Anspruch ist es, Projekte in Time & Budget, agil und mit höchstem Qualitätsanspruch umzusetzen und dabei stets innovativ zu sein. Ganz gleich, welche Anforderungen unsere Kunden stellen, dank unserer breiten technischen Expertise können wir ganz individuelle Ansprüche realisieren und verschiedenste Systeme miteinander integrieren, ohne dass die Performance oder Qualität darunter leidet. Hierfür setzen wir auf ein starkes Netzwerk aus Technologieanbietern und einer langjährigen Forschungskultur.
Neofonie zählt laut aktuellem Internetagentur-Ranking zu den Top-10 in der Plattform Entwicklung und ist erst kürzlich mit dem Deep Tech Award 2023 ausgezeichnet worden.
Digitale Kompetenz für Ihren digitalen Fortschritt
Unsere Kompetenzfelder

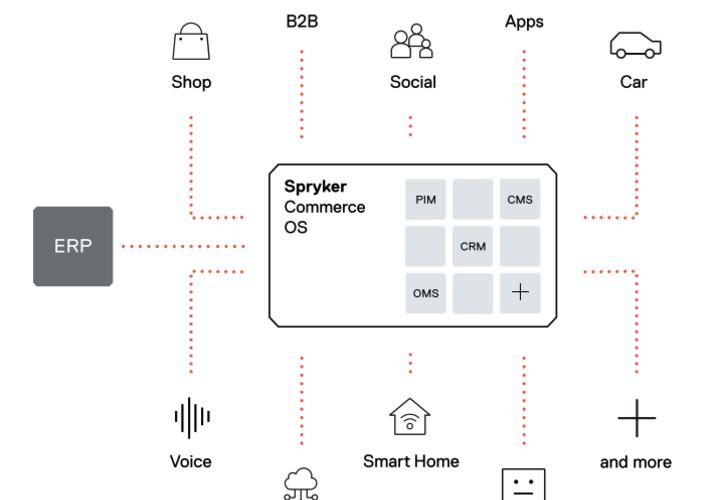
Commerce
Jede E-Commerce-Lösung ist so individuell wie ihr Business und ihre Kunden. Wir integrieren und erweitern dabei bestehende Shopsysteme oder entwickeln komplett individuell. Ob für B2B oder B2C – wir gestalten Commerce Welten, die Nutzer begeistern.

Content
Von Content Management bis zur Digital Experience Plattform – wir schaffen digitale Erlebniswelten. Wir begleiten Sie von der Evaluation und Auswahl des passenden CMS, über die Implementierung bis hin zur Individualisierung Ihres spezifischen Content-Systems.

KI
Von Text Mining zur intelligenten Suche – wir erschließen Insights aus Texten und bringen Sie an Ihre User. Unsere Text Mining Kompetenz helfen wir Ihnen bei der Auswertung, Strukturierung, Anreicherung und Monitoring von Texten.

Apps & Co
Apps, IoT, VR und AR – gemeinsam schaffen wir mobile Anwendungen, die zu Ihren geschäftlichen Anforderungen passen und Nutzern Spaß machen. Wir begleiten Sie von der Konzeption über das Design bis hin zur finalen Entwicklung Ihrer individuellen App.


































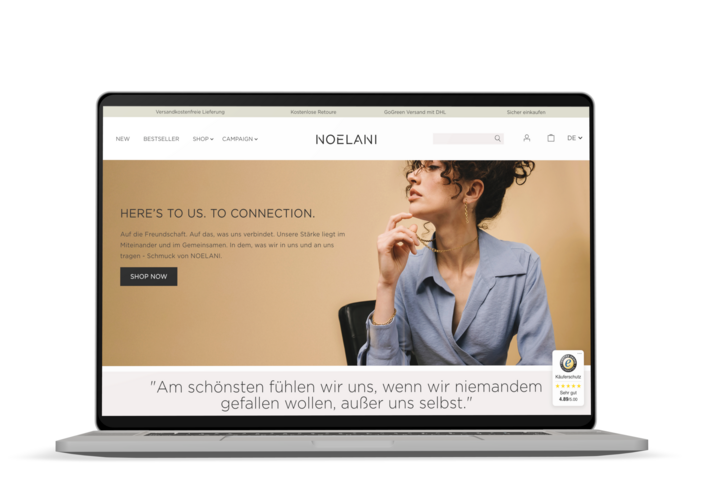




























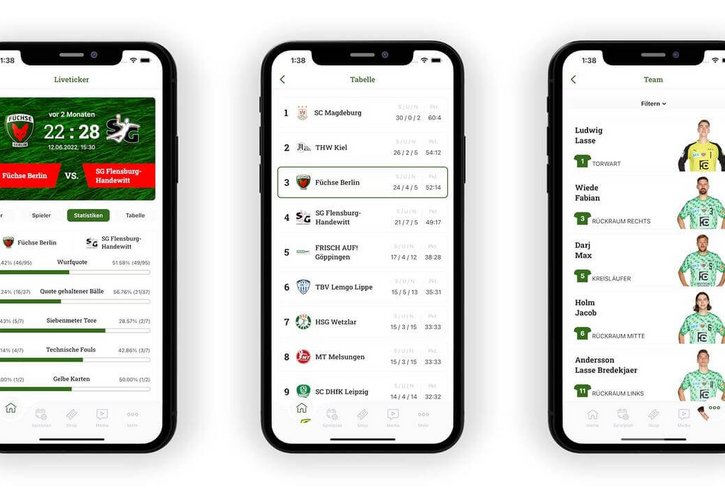
Das könnte Sie interessieren
Neues von Neofonie





















































































































Newsletter
Unser Newsletter „Neo Report“ vermittelt konkretes Praxiswissen, Trends und Know-how für Ihr digitales Business – quartalsweise und kompakt. Jetzt anmelden.
Karriere und Jobs
Komm in unser Team
Wir bei Neofonie leben Vielfalt. Tag für Tag arbeiten wir gemeinsam daran, unseren Kunden zukunftsorientierte und individuelle Softwarelösungen zu bieten. Dabei hast Du immer die Chance Deine Ideen einzubringen und gleichzeitig Projekte voranzutreiben. Neben dem agilen Projektgeschäft ist auch der Bereich KI ein wesentlicher Bestandteil unseres Erfolgs. Arbeiten bei Neofonie heißt, die digitale Welt mitzugestalten, mit rund 180 Kollegen aus 19 Nationen, vielfältigen Projekten, unterschiedlichen Kunden und Spaß. Wenn Du Lust hast auf eine abwechslungsreiche und spannende Tätigkeit in unserem Team, dann schaue Dir einfach unsere Jobangebote an oder bewirb Dich initiativ.
