Semantische Textanalyse
Machen Sie sich Texte zu Nutze
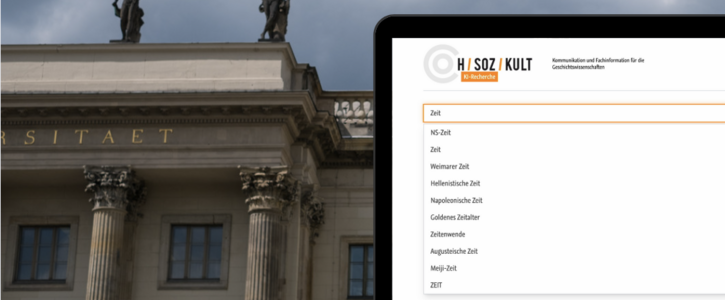
Unsere spezialisierte Text Mining Beratung erlaubt Ihnen die vollumfängliche, automatisierte Auswertung sämtlicher Arten von vorliegenden Texten. Hierbei kann diese innovative Technologie auch ein integraler Bestandteil einer umfassenden Big-Data-Analyse innerhalb Ihrer IT-Infrastruktur sein. Wenn es beispielsweise konkret darum geht, Texte semantisch hochwertig aufzubereiten, erzielen wir durch intelligente Klassen sowie präzise Schlagworte eine deutlich verbesserte Datenqualität.
Zudem unterstützt unser fortschrittlicher Dienst die automatisierte Erstellung von Themen-Portalen (Topic Pages) sowie die intelligente interne Verlinkung Ihrer gesamten Inhalte. Folglich entsteht eine wesentlich dichtere sowie sinnvollere Verlinkungsstruktur, welche die Navigation für Ihre Nutzer spürbar vereinfacht und gleichzeitig Ihre Suchmaschinen-Optimierung (SEO) nachhaltig fördert. Darüber hinaus können Sie hierdurch behandelte Personen, Organisationen sowie geografische Orte in Sekundenbruchteilen ermitteln und für Ihre Geschäftsprozesse nutzbar machen.
Anwendungsgebiete der Textanalyse
Erstellung von Themenseiten
Eine moderne Text Mining Beratung ermöglicht die hocheffiziente Erstellung automatisierter Themenseiten. Hierbei analysiert und bündelt die KI sämtliche relevanten Datenbestände aus Ihren Archiven, sodass Sie alle Inhalte mit minimalem manuellem Aufwand zentral kuratieren können. Folglich präsentieren Sie Ihren Besuchern ein thematisch konsistentes Informationsangebot, welches alle wichtigen Aspekte übersichtlich zusammenfasst. Zudem finden Ihre Nutzer somit alle relevanten Informationen direkt an einem Ort vor, was die Verweildauer auf Ihrer Plattform deutlich erhöht.
Trendanalysen
Mithilfe unserer Expertise im Bereich Textanalyse erkennen Sie künftig Marktentwicklungen und Trends deutlich früher als Ihre Wettbewerber. Im Rahmen der **Text Mining Beratung** lassen sich nämlich gewaltige Daten- sowie Textmengen aus verschiedensten Quellen automatisiert auswerten. Hierbei erhalten Sie jederzeit einen präzisen Überblick über die aktuell wichtigsten Themenfelder Ihrer Branche. Folglich sind Sie in der Lage, neue Entwicklungen sofort zu identifizieren und strategisch darauf zu reagieren.
Produktkataloge
Optimieren Sie Ihre E-Commerce-Plattform durch die automatische Generierung hochwertiger Produktbeschreibungen. Hierbei erstellen wir mithilfe von KI-basierter Textanalyse dynamische Produkttexte, welche stets die aktuellsten Merkmale und Spezifikationen beinhalten. Zudem werden diese Inhalte so optimiert, dass sie Ihre Kunden gezielt zum Kauf anregen und die Conversion-Rate steigern. Folglich entlasten Sie Ihre Content-Teams massiv von repetitiven Schreibaufgaben.
Marktrecherche & SEO-Optimierung
Unsere Text Mining Beratung lässt sich ebenso exzellent für eine datengestützte SEO-Optimierung sowie Marktrecherche einsetzen. Hierbei analysieren wir tiefgreifend, welche spezifischen Keywords Ihre direkten Mitbewerber erfolgreich verwenden. Zudem machen wir sichtbar, in welchem semantischen Umfeld sich die Konkurrenz positioniert, um ungenutzte Content-Potenziale für Sie aufzudecken. Folglich können Sie Ihre eigene Strategie präzise anpassen und Ihre Rankings nachhaltig verbessern.
Brand & Social Media Monitoring
Behalten Sie jederzeit die volle Kontrolle darüber, wie über Ihre Brand über sämtliche digitalen Kanäle hinweg gesprochen wird. Besonders innerhalb der sozialen Netzwerke ist es heutzutage entscheidend zu wissen, wie die aktuelle Stimmung in Bezug auf Ihre Marke ist. Hierbei nutzen wir Sentiment-Analysen, um positive oder negative Trends in Echtzeit zu identifizieren. Folglich können Sie umgehend passende Kommunikationsmaßnahmen erarbeiten und proaktiv einleiten.
Anreicherung von Suchergebnissen
Steigern Sie die Relevanz Ihrer On-Site-Suche durch eine intelligente Anreicherung der angezeigten Ergebnisse. Hierbei verknüpfen wir Ihre Suchergebnisse automatisiert mit weiteren relevanten Texten oder ergänzenden Medien wie Bildern und Audio-Dateien. Zudem sorgt die Text Mining Beratung dafür, dass Nutzer schneller genau das finden, wonach sie suchen. Folglich verbessert sich die User Experience auf Ihrer Website spürbar.
Reputationsmanagement
Seien Sie Ihren Kunden durch intelligentes Reputationsmanagement stets voraus. Hierbei analysieren wir das Nutzerverhalten und wichtige Textbewertungen. Zudem schlagen wir individuell passende Produkte für Käufer vor. Folglich stärken Sie das Vertrauen in Ihre Marke nachhaltig. Schließlich werten wir auch massive Textmengen aus dem Support aus. Dadurch senken Sie operative Kosten bei hoher Servicequalität. Weiterführende Details zur Sprachtechnologie finden Sie auch bei der Gesellschaft für Sprachtechnologie und Computerlinguistik.
Auswertung von Textmengen
Mithilfe großflächiger Auswertungen massiver Textmengen identifizieren wir für Sie zuverlässig wiederkehrende Kundenanfragen. Hierbei können Sie künftig effizient sowie vollautomatisiert die passenden Antworten ausspielen. Folglich entlasten Sie Ihren Support-Bereich massiv von Routineaufgaben und verkürzen gleichzeitig die Antwortzeiten für Ihre Kunden. Schließlich führt diese Automatisierung zu einer deutlichen Senkung der operativen Kosten bei gleichbleibend hoher Servicequalität.
Whitepaper
Textanalyse in der Cloud
Der größte Teil der Daten liegt in unstrukturierter Form vor und zum beträchtlichen Teil handelt es sich hierbei um Texte, zum Beispiel in Form von Artikeln, Dokumenten, E-Mails, Websites, Befragungen, Studien oder Beiträgen. In unserem Whitepaper „Textanalyse aus der Wolke“ geben wir einen ausführlichen Überblick über die Bedeutung der Textanalyse, über Anwendungsgebiete und Tools und stellen konkrete Textanalyse Beispiele vor.