Themenmonitoring | Top-Themen automatisiert identifizieren
Um aus der Vielzahl der täglich erscheinenden Veröffentlichungen den Überblick zu behalten und unternehmens- oder trendrelevante Themen identifizieren zu können, kommen Monitoringtools zum Einsatz. Peter Adolphs gibt einen Einblick in die Möglichkeiten des Themenmonitorings und zeigt, welche semantischen Technologien dahinter stecken.
Die Trend- und Konkurrenzanalyse gehört in Medienunternehmen und PR Abteilungen zum täglichen Business – insbesondere im Onlinebereich. Kein Unternehmen will schließlich ein wichtiges Thema in der eigenen Berichterstattung auslassen, oder die Aktivitäten der Konkurrenz außer acht lassen. Auch im Rahmen der eigenen Content Strategie ist die Analyse von Top-Themen relevant, um hohe Trafficzahlen zu erzielen oder die eigene Sichtbarkeit zu erhöhen.
Um die Vielzahl der Nachrichtenquellen im Auge behalten zu können, sind Monitoringtool unabdingbar, die nach Themen unterscheiden können.
Wie funktioniert Themenmonitoring?
Im Rahmen des Forschungsprojektes News-Stream, welches Neofonie zusammen mit den Partnern Fraunhofer IAIS, dpa und Deutsche Welle durchführt und durch das Bundesministerium für Bildung und Forschung gefördert wird, wurde ein Topic Monitoring Tool erstellt, dass Nachrichtenmeldungen automatisch thematisch clustert. Das Clustering-Verfahren ordnet jeden Artikel einem Thema automatisch zu, wobei Ähnlichkeiten durch maschinelles Lernen erkannt und zusammengeführt werden. Die Basis bilden hierfür Schlagworte, Phrasen und Entität wie Ort, Personen oder Organsationen, die in dem Artikel besonders häufig auftauchen. Anhand der Cluster können so schnell Top Themen identifiziert und visualisiert werden.
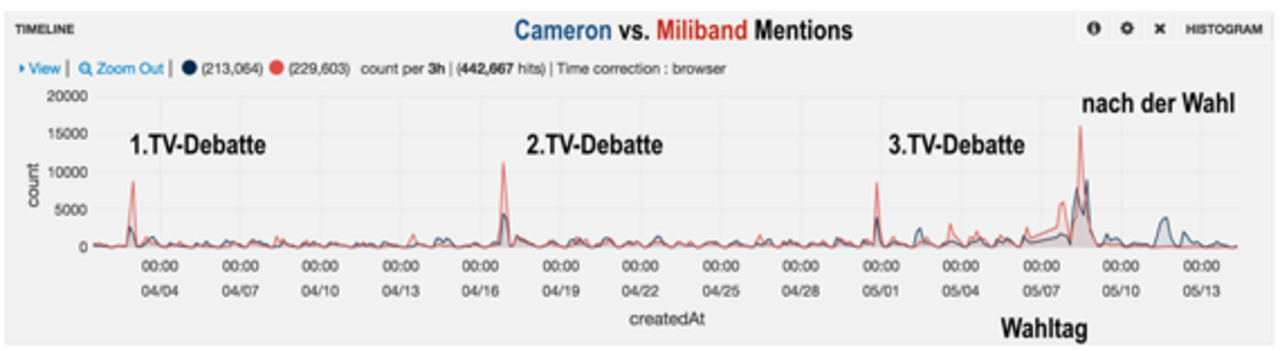
Big Data für Journalisten – Twitter Analyse der britischen Unterhauswahlen
Twitter ist für viele Journalisten eine der primären Informationsquellen, wenn es um die Analyse von Social-Media-Inhalten oder Breaking-News-Ereignisse geht. Im Rahmen des Forschungsprojektes „News-Stream 3.0“ wurde ein Demonstrator entwickelt, der Twitter-Analysen auf einfache Weise ermöglicht.
Damit Journalisten und Redakteuren den kontinuierlich, ständig wachsenden Daten- und Informationsstrom in Echtzeit bändigen können, entstehen im Forschungsprojekt „News-Stream 3.0″ Recherchetools, die große Datenmengen aus Videos, sozialen Netzwerken, Blogs und Archiven bündeln und die wichtigsten Informationen gezielt bereitstellen. Twitter stellt in diesem Zusammenhang eine erste Datenquelle dar.
Zu den britischen Unterhauswahlen 2015 wurde ein erster Demonstrator umgesetzt, mit dem sich die Twitter-Reaktionen auf die Wahldebatten verfolgen lassen. Das Kopf-an-Kopf-Rennen der Parteien lässt sich an einem Zeitstrahl ablesen, auf dem die Anzahl der Tweets von Labour und Tories verglichen wird.
Big-Data-Infrastruktur
Aus journalistischer Sicht sollte sich der Demonstrator unbedingt von starren Datendashboards lösen und Journalisten mehr Flexibilität bei der Datenaufbereitung, -analyse und -visualisierung geben. Interessant sind an dieser Stelle deshalb weniger die Ergebnisse der Analyse, sondern die verwendeten Technologien. Hinter dem Demonstrator steht eine ausgewachsene Big-Data-Infrastruktur: ein Hadoop-Cluster mit 16 Nodes und einer Speicherkapazität von insgesamt 100 Terabyte, auf dem Clouderas Open-Source-Distribution betrieben wird, die sowohl eine verteilte Stapelverarbeitung als auch die Echtzeitanalyse mit Apache Spark ermöglicht. Für die performante Auslieferung von Daten bindet Cloudera die verteilte Open-Source-Suchlösung Apache Solr an.
Logfile-Analyse setzt sich durch
Das verwendete Dashboard stammt aus einem anderen Kontext, nämlich der Logfile-Analyse. Während Big Data für viele Unternehmen bisher noch kein Thema ist, hat sich im IT-Betrieb die kollaborative Auswertung von großen Mengen von Logfiles durchgesetzt – auch dank des interaktiven Dashboards “Kibana”, das ursprünglich als Demo-Applikation für die Open-Source-Suche Elasticsearch entwickelt wurde. Ebenso wie Twitter ist auch bei Logfiles die Zeit die wichtigste Dimension: hier geht es z.B. um die Anzahl der Nutzer oder der Fehlermeldungen pro Zeiteinheit. Mit wenigen Klicks lässt sich bei Kibana ein neues Dashboard als Kopie erstellen oder ein Widget hinzufügen.
Die Auswahl reicht von Säulen- und Tortendiagrammen über Kartendarstellungen bis zu Tagclouds und Listen. Flexibilität ist für die Nutzer von Loganalyse-Tools zentral: wenn z.B. zusätzliche Informationen geloggt werden, muss es einfach möglich sein, auf diese Informationen zuzugreifen und sie im Dahsboard anzuzeigen. Eine gute Benutzbarkeit ist angesichts der hektischen Arbeitsbedingungen im IT-Betrieb ebenfalls von großer Bedeutung.
Die Ähnlichkeit zu den Anforderungen von Redakteuren sind frappierend. Es lag daher nahe, ein Dashboard wie “Kibana” für die Twitter-Analyse zu verwenden. Um eine nahtlose Integration in Clouderas CDH zu ermöglichen, wurde auf einen Entwicklungszweig von Kibana mit Namen “Banana” zurückgegriffen.
Textanalyse deckt die Top-Themen für 2016 auf
Newsportale informieren uns tagtäglich über die neusten Entwicklungen in sämtlichen Branchen weltweit. Ein Großteil dieser News beeinflusst unsere Einstellungen und potenziellen Entscheidungen bezüglich kommender Entwicklungen in Politik, Wirtschaft und Co. Besonders zum Ende des Jahres ist es spannend zu rekapitulieren, welche Themen besondere Brisanz in den Medien hatten. Journalisten und Redakteure greifen in ihren Artikeln nicht nur Trends auf, sondern lassen auch Tendenzen für die bevorstehenden Top-Themen erkennen. Neofonie hat 14 deutschsprachige Portale für IT-News analysiert, die zusammen über 40 Mio. Mal pro Monat aufgerufen werden (Page Impressions), und zusätzlich sechs Technologie-Experten aus dem eigenen Haus befragt, um herauszufinden, wo die Reise 2016 hingeht.
Reaktive Programmierung wird salonfähig
André Leichsenring, Head of Projects: „Plattformen wie Node.js und Vert.x haben ihre Praxistauglichkeit bewiesen. Reaktive Applikationen und Architekturen werden im Jahr 2016 weiter zunehmen. In diesem Bereich, aber auch generell, wird die Bedeutung von JavaScript weiter zunehmen, da sie bereits heute auf den unterschiedlichsten Geräte-Plattformen verfügbar ist und auch langfristig im Internet-of-Things und In-Car Systemen als kleinster gemeinsamer Nenner in der Programmierung dienen kann.“
Darüber schreiben die Medien: “JavaScript” war mit 1.700 Nennungen im Jahr 2015 in den Redaktionen sehr beliebt und wird auch im nächsten Jahr eines der Evergreens bleiben. Im Bereich der reaktiven Plattformen wird “Vert.x” im Vergleich zu “Node.js”, hierzu gab es 459 Nennungen, in den IT-Medien noch(!) relativ stiefmütterlich behandelt. Die Tendenz ist jedoch eindeutig und lässt vermuten, dass in 2016 verstärkt “Vert.x” erwähnt werden wird.
Agilität in allen Bereichen
Ender Özgür, Head of Software Factories: “Agile Methoden und Konzepte wie Scrum, Kanban oder DevOps werden weiterhin integraler Bestandteil in der Projektarbeit mit unseren Kunden sein. Dabei werden neue Best-Practices aus der agilen Community und technische Weiterentwicklungen im Bereich Continuous Delivery wichtige Voraussetzungen für erfolgreiche Produkte schaffen.“
Darüber schreiben die Medien: Im Bereich der agilen Projektmanagement Methoden haben “Scrum” und “Kanban” ihren festen Platz, obgleich “Scrum” im Vergleich zu” Kanban” rund dreimal so viele Nennungen in redaktionellen Beiträgen erhielt. In der Presse wurde “Scrum“ insgesamt 191 Mal thematisiert. Der Begriff “Agile” wurde 140 Mal aufgegriffen und lässt eine eindeutige Tendenz für 2016 erkennen: Der Stellenwert des Begriffs in den Redaktionen nimmt weiter zu.
Please touch the running system
André Hirsinger, Technical Chief of ASP: “Trotz hoher Anforderungen im Bereich 24×7 Verfügbarkeit, gibt es eine deutliche Tendenz weg vom konservativen statischen “don’t touch a running system” hin zu einer agilen Herangehensweise. Hier überwiegt der Vorteil kürzerer Entwicklungszyklen. Zusätzlich resultiert daraus aber auch eine Architekturanforderung, weg vom Monolithen und hin zu kleinteiligen Microservices. Container-Technologien etablieren sich in diesem Kontext zunehmend.”
Darüber schreiben die Medien: Die Analyse der IT-Newsportale hat ergeben, dass “Microservices” in den IT-Medien 2015 ein Dauerthema ist. Über “DevOps” wurde seit dem Sommer 2015 deutlich verstärkt berichtet – Tendenz steigend. Im November ist “DevOps” mit insgesamt 552 Nennungen am Thema “Microservices” mit 486 Erwähnungen sogar vorbeigezogen. “Docker” war das Lieblingsthema der IT-Redaktionen im ersten Halbjahr und hat sich seit Mitte des Jahres zu Gunsten von “Container”-Technologien im Allgemeinen verschoben. “Docker” wurde 1.205 Mal genannt!
Die Informationen sind überall
Stefan Gerstmeier, COO, Neofonie Mobile: „Mobile Endgeräte sind aus unserem privaten und beruflichen Alltag nicht mehr wegzudenken. Die Zahl der intelligenten, mit Sensoren ausgestatteten Endgeräte, wird in 2016 massiv zunehmen und unterschiedlichste Informationen erfassen. Durch das Zusammenspiel und die Interaktion der Endgeräte untereinander, entsteht das 'Information-of-Everything'. Im passenden Kontext können diese Informationen echte Mehrwerte für mobile Nutzer schaffen. Diese veränderte Technologie- und Datenlandschaft wird im kommenden Jahr verstärkt die App-Entwicklung beeinflussen.“
Darüber schreiben die Medien: Über die Schnittstellen “Bluetooth” und “NFC” wird in redaktionellen Beiträgen regelmäßig geschrieben. Während “NFC” mit 576 Nennungen über das gesamte Jahr betrachtet stagniert, wird “Bluetooth” rund dreifach so häufig genannt – Tendenz steigend. “IoT”, die Abkürzung für Internet-of-Things, schafft es in 2015 auf 908 Nennungen, noch vor “VR”, das für Virtual Reality steht, mit 656 Erwähnungen.
Mehr Freiraum durch adaptives Design
Gunnar Graupner, ehemaliger Head of UX: „Es kommen immer mehr mobile Endgeräte mit unterschiedlichen Displaygrößen auf den Markt. Ganz gleich ob Smartwatch oder Tablet, die gute User Experience (UX), muss auf die unterschiedlichen Device-Größen reagieren. Diese Herausforderung wird sich 2016 vervielfachen. Herkömmliche Responsive Design Verfahren stoßen an ihre Grenzen. Der Trend geht in Richtung Adaptive Designs. Nutzungskontext und Device-spezifische Eigenschaften und Features können bei diesem Ansatz besser in Einklang gebracht werden.“
Darüber schreiben die Medien: IT-News Portale haben in 2015 deutlich häufiger über “Responsive” als über “Adaptive” geschrieben. Es ist jedoch ein stetig steigendes Interesse zugunsten von “Adaptive” zu beobachten.
Smart sind nicht Daten, sondern die Fähigkeit Daten zu analysieren
Peter Adolphs, ehemaliger Head of Research: „In Textdokumenten wie beispielsweise redaktionellen Artikeln, stecken wertvolle Informationen, die Sie sich mit sogenannten Textmining-Technologien automatisiert analysieren lassen. Semantische Technologien sind mittlerweile im Alltag angekommen und wirken im Hintergrund, sei es bei Suche von Texten, digitalen Assistenten, der Ausspielung von passgenauer Werbung oder inhaltsbasierter Empfehlung. Sie ergänzen damit statistische Verfahren, wie maschinelles Lernen. Spannend wird es, wie 2016 semantische Technologien helfen werden, nicht-textuelle Inhalte wie Bilder oder Videos anzureichern und zu strukturieren.”
Darüber schreiben die Medien: Die Datenanalyse hat viele Ausprägungen. Wenn große Datenmengen aus unterschiedlichen Datenquellen quasi in Echtzeit zu relevanten Informationen führen, spricht man von “Big Data”. Auf IT-News-Portalen wurde seit Januar über 1000 Mal über “Big Data” geschrieben. Das starke Interesse seitens der Redakteure wird in den nächsten Monaten mit rund 100 Erwähnungen monatlich tendenziell weiter stabil bleiben. “Smart Data” hingegen hat mit gerade mal 43 Nennungen seit Januar in den IT-Medien kaum Interesse geweckt.
Neofonie zählt bundesweit zu den führenden Spezialisten im Bereich der Textanalyse. Auch im weltweiten Vergleich kann sich das Berliner IT-Unternehmen sehen lassen: Beim „Entity Recognition and Disambiguation Challenge 2014“ von Microsoft und Google belegte Neofonie weltweit den sechsten Platz, in puncto Geschwindigkeit sogar den zweiten. Das Know-how bringt Neofonie regelmäßig in Forschungsprojekte ein. So auch in “News-Stream 3.0”, einem Forschungsprojekt des Bundeministerium für Bildung und Forschung (BMBF). Gemeinsam mit den Partnern Fraunhofer IAIS, Deutsche Welle und dpa-infocom entsteht eine Big Data Infrastruktur für Journalisten.
Im Whitepaper “Textanalyse aus der Wolke” erhalten Sie einen ausführlichen Überblick über Möglichkeiten, Herausforderungen und Techniken der semantischen Textanalyse mit konkreten Beispielen.
Zum kostenlosen Whitepaper
Textanalyse soll ausgeweitet werden
Die Twitter-Analyse ist nur der Anfang. Im nächsten Schritt wird es darum gehen, eine Vielzahl von Quellen anzubinden und die Nutzungsmuster der Redakteure zu untersuchen. Ergebnisse der im Projekt entwickelten Textanalyse-Algorithmen werden an die Stelle der vom Datenanbieter wie Twitter gelieferten Metadaten treten. Durch die semantische Analyse von Texten und die anschließende automatisierte Verschlagwortung der Texte kann der Redakteur in Sekundenschnelle verfolgen, was auf Blogs, über Twitter oder in anderen sozialen Medien berichtet oder diskutiert wird. Der aktuelle Demonstrator dient dabei als Baukasten. Eine Aufgabe wird der Export von Widgets bzw. der ermittelten Datensätze für die Nutzung in anderen Formaten und Applikationen sein. Auch die visuelle Weiterentwicklung spielt eine Rolle – auch hier ist für eine einfache Erweiterbarkeit gesorgt, da die gewählte Lösung auf der im Datenjournalismus beliebten Open-Source-Bibliothek D3.js basiert.
Wie sich mit TXT Werk Twitter beherrschen lässt
Um im Zeitalter des Datenüberflusses relevante Informationen extrahieren zu können, sind neue Tools notwendig. Beim Hackathon-Event „Content Hack Day“ Ende November trafen sich Entwickler, um binnen 48 Stunden geeignete Tools zu entwickeln. Theresa Grotendorst und Julia Bode haben auf Basis der TXT Werk API eine Anwendung für Twitter entwickelt. Die Anwendung „My Twitter Bacon“ analysiert und kategorisiert die in den Tweets verlinkten Webseiten unter semantischen Gesichtspunkten. Der Nutzer kann so die für ihn relevanten Informationen einfacher und schneller erfassen. Neo Tech Blog hat die Entwicklerinnen interviewt.
Wie entstand die Idee für „My Twitter Bacon“?
Die Idee ist durch einen tatsächlichen Bedarf entstanden. Ähnlich wie wir, nutzen viele Leute Twitter vornehmlich zum Medienkonsum, denn es werden viele Links zu interessanten (Fach-)Artikeln gepostet. Allerdings fehlt meist der Kontext. Da jeder Tweet nur 140 Zeichen hat, reicht der Platz oft nicht aus, um in knappen Worten zu beschreiben, um welches Thema es überhaupt geht und warum der verlinkte Content interessant ist. Hinzu kommt, dass aktive Twitter-Nutzer im Schnitt über 100 anderen Nutzern folgen, da verliert man schnell den Überblick – Stichwort „Information Overload“. Wir hatten die Idee ein Tool zu entwickeln, dass die verlinkten Inhalte aus unserer Twitter-Timeline automatisch extrahiert und kategorisiert. So, dass wir als Nutzer einen schnelleren Überblick über die für uns relevanten Inhalte bekommen.
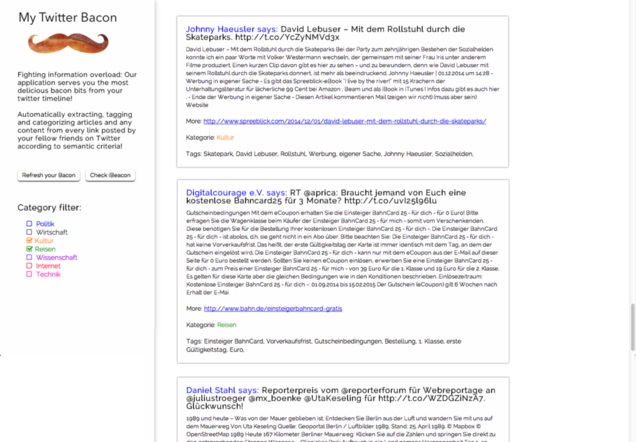
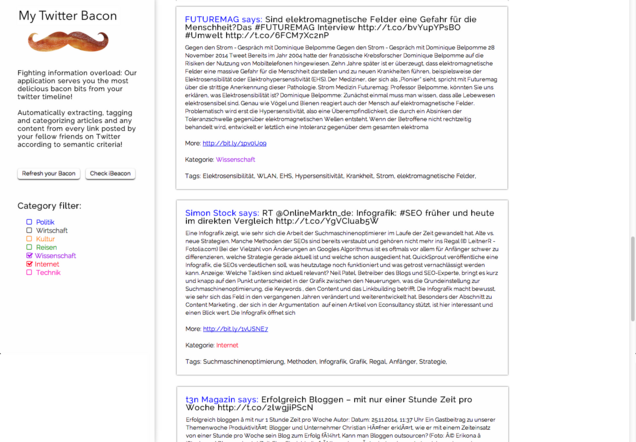
Wie funktioniert die Anwendung?
Unsere Anwendung parst alle Tweets aus der Twitter-Timeline die einen Link enthalten und extrahiert den Content „hinter“ dem Link. Der Content wir dann über die TXT Werk API semantisch analysiert, automatisch getagged und kategorisiert (Politik, Kultur, Reise, Internet, Wissenschaft etc.). Unsere Anwendung zeigt schließlich einen Feed aller Inhalte die deine Twitter-Freunde geteilt und empfohlen haben. Diese Inhalte können dann mittels der Kategorien gefiltert werden, z.B.: „Zeige mir nur Inhalte zum Thema Internet und Wissenschaft“. Anhand der zusätzlichen Tags, erkennt man außerdem noch schneller, ob ein Artikel interessant ist oder nicht. So ist es nicht mehr nötig, die eigene “überflutete” Twitter-Timeline nach interessanten Inhalten/Artikeln zudurchforsten und immer wieder auf Links zu klicken, welche dann doch nicht interessant oder relevant für einen sind.
Zusätzlich haben wir noch begonnen, eine Schnittstelle zu einem Beacon einzubauen. Dadurch sollte es möglich sein, je nach Lokalität und Zeit nur Inhalte bestimmter Kategorien anzuzeigen. So wird man z.B. im Büro nur arbeitsspezifische Inhalte/Tweets sehen. In Anlehnung an das Wort „Beacon“ sind wir auch auf den Namen unseres Tools gekommen „Twitter Bacon“.
Warum habt ihr euch für die TXT Werk API entschieden?
Wir fanden die TXT Werk API sehr spannend, da sie es uns ermöglicht hat, den unstrukturierten Inhalten einen semantischen Kontext zu geben. Wir waren erstaunt, wie gut Kategorie-Klassifikation und Keyword-Extraktion (Tagging) funktioniert haben. In Zukunft wird die semantische Analyse und Auszeichnung von Inhalten eine zunehmend wichtige Rolle spielen, da so die Bedeutung von Informationen für Computer verwertbar gemacht werden kann. Dadurch ergeben sich spannende neue Anwendungsszenarien, wie z.B. semantische Empfehlungssysteme oder die automatische Anreicherung mit Zusatzinformationen durch Linked Open Data.
Wie seid ihr technisch vorgegangen?
Zunächst haben wir uns überlegt welche Funktionen unser Tool umfassen soll. Bei der Konzeption stellte sich heraus, dass viele Funktionen in so kurzer Zeit nicht realisierbar sind. Das heißt, wir mussten Abstriche machen und priorisieren. Nur die Funktionen, die unbedingt nötig sind, um den eigentlichen Zweck des Anwendung zu ermöglichen, wurden eingebaut – ähnlich wie bei einem „Minimum Viable Product“ in der Lean Startup Methodik. Julia hat dann das Backend mit Javascript und PHP entwickelt, um die Twitter-API und TXT Werk API anzubinden, Theresa hat parallel das Frontend in HTML/CSS umgesetzt. Die größte Herausforderung lag beim Einbinden der Twitter-API. Das “Rate Limit” war beim Testen immer sehr schnell aufgebraucht, daher mussten wir einen Cache einbauen, der nur alle 10 min die Tweets erneut abruft und die alten zwischenspeichert.
Habt ihr Ideen, wie das Tool weiter optimiert werden kann?
Julia hätte gerne die Beacon-Schnittstelle weiter ausgebaut, um die Inhalte kontext-sensitiv darzustellen. Außerdem wäre es wichtig, die Performance zu verbessern. Man muss im Moment doch einige Sekunden warten, bevor der Request zurück kommt und die Inhalte angezeigt werden. Theresa hätte gerne alle durch die TXT Werk API identifizierten Entitäten (Personen, Orte und Organisationen etc.) mit den URIs aus dem Freebase Knowledge Graph verlinkt, um sie als Linked Open Data zu vernetzen. Das wäre eine tolle semantische Anreicherung der Inhalte, damit sich der Anwender bei Interesse noch tiefergehend mit einer Thematik beschäftigen kann. Aber leider hat die Zeit beim Hackathon für diese Optimierungen nicht mehr gereicht, es gibt also noch einiges zu tun. Man könnte das Tool außerdem so erweitern, dass nicht nur die eigene Twitter-Timeline bzgl. geteilter Inhalte analysiert wird, sondern auch andere Social Media Dienste. Das User Interface könnte natürlich auch noch schöner gestaltet werden!
Was hat euch an der Teilnahme am Content Hack Day gereizt?
Wir sind immer wieder begeistert, wie sich auf einem Hackathon innerhalb von 48 Stunden innovative Ideen zu einem fertigen Prototypen entwickeln. Dabei ist es toll zu sehen, welche Synergien sich zwischen Designern, Entwicklern und anderen Teilnehmern ergeben. Die Gruppendynamik und die Ergebnisse sind oft beeindruckend und das, obwohl der Zeitdruck hoch ist und sich die meisten Leute vorher nicht kennen. Im Berufsalltag arbeiten die Leute einzelner Fachbereiche leider selten so intensiv zusammen.
Wie kam euer Team zustande?
Wir haben uns letztes Jahr bei einem anderen Hackathon in Berlin kennengelernt. Seitdem treffen wir uns immer mal wieder auf Veranstaltungen und Konferenzen in Hamburg und Berlin. Da wir beide von unserer Idee begeistert waren, war schnell klar, dass wir gemeinsam daran arbeiten möchten.
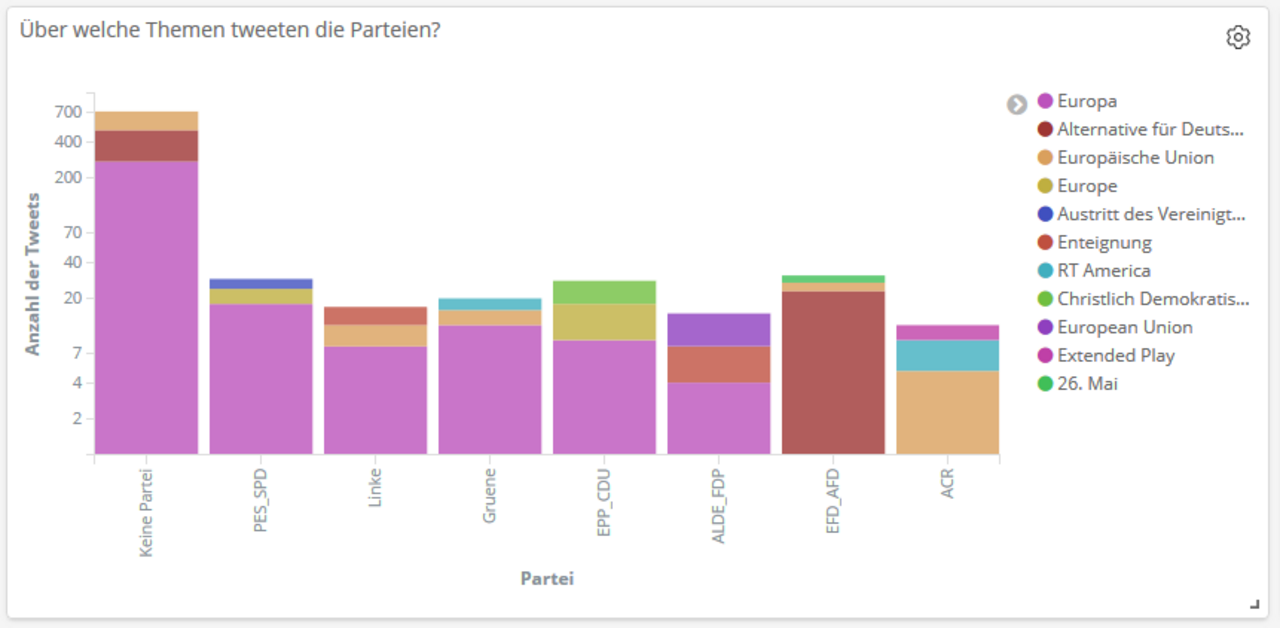
Twitter Analyse: Aktuelle Trends zur Europawahl 2019
Für die Analyse machen wir uns die Textanalyse-Fähigkeiten unseres hauseigenen Frameworks TXT Werk zunutze. Es ist unter anderem in der Lage, in einem Text auftretende Entitäten wie Personen, Orte aber auch Konzepte zu erkennen. Mit Hilfe von TXT Werk extrahieren wir die relevanten Themen aus Tweets mit Bezug zur Europawahl. Darüber hinaus erfassen wir weitere Parameter wie z.B. den Zeitpunkt, an dem die betreffenden Tweets gepostet wurden, eventuell geäußerte Stimmungen, aber auch die mediale Reichweite der einzelnen Parteien. Eine Aufbereitung der gesammelten Daten realisieren wir mit Hilfe von Elasticsearch und Kibana.
Basierend auf dieser Analyse lässt sich einfach erkennen, welche Themen die Debatten um die Europawahl auf Twitter beherrschen. Zwei Trends fallen dabei direkt ins Auge:
1. In der näheren Betrachtung der Bundestagsparteien fällt auf, dass die Parteien CDU/CSU, SPD, die Grünen, die Linke und FDP bei der Europawahl vorrangig das gemeinsame Thema „Europa“ in den Mittelpunkt rücken, während die AfD durchgehend sich selbst benennt und thematisiert.
2. Die Parteivertreter diskutieren viele verschiedene Themen in Bezug auf die Europawahl mit der Twitter-Community. Allerdings tun sie sich bislang schwer, thematisch nicht nur auf aktuelle Ereignisse zu reagieren, sondern den Diskurs auf ein klares Parteiprogramm für ihre Europapolitik zu lenken.
Peter Adolphs erklärt im folgenden Video, warum Topic Monitoring an Bedeutung, vor allem für Journalisten, gewinnt und wie die Themenidentifizierung funktioniert.
Im Whitepaper “Textanalyse aus der Wolke” erhalten Sie einen ausführlichen Überblick über Möglichkeiten, Herausforderungen und Techniken der semantischen Textanalyse mit konkreten Beispielen.
Weitere Informationen zu News-Stream
– News-Stream Website
– Deutschlandradio Kultur: News-Stream“ auf der CeBIT: Eine Software soll Big Data bändigen
Veröffentlichung am 18.02.2016, aktualisiert am 18.10.2020
Bildquelle: unsplash, AbsolutVision

Das könnte sie auch interessieren